Data Science and Engineering: MA Computing Projects (PROJ-H-402) and Master's Thesis Topics (MEMO-H-504)
This page contains a list of project supervised by academic members of the Data Science and Engineering laboratory. The projects concern both MA Computing Projects (PROJ-H-402) and Master's Thesis Topics (MEMO-H-504).
Note: The course PROJ-H-402 is managed by Pr. Mauro Birattari; please refer to the course description page for the rules concerning the project. The course MEMO-H-504 is managed by Pr. Dimitris Sacharidis; please refer to the course description page for more information.
The projects listed below are organized by topic:
Mobility Databases
Mobility databases (MOD) are database systems that can store and manage moving object geospatial trajectory data. A moving object is an object that changes its location over time (e.g., a car driving on the road network). Using a variety of sensors, the location tracks of moving objects can be recorded in digital formats. A MOD, then, helps storing and querying such data. A couple of prototype systems have been proposed by research groups. Yet, a mainstream system is by far still missing. By mainstream we mean that the development builds on widely accepted tools, that are actively being maintained and developed. A mainstream system would exploit the functionality of these tools, and would maximize the reuse of their ecosystems. As a result, it becomes more closer to end users, and easily adopted in the industry.
Towards filling this gap, our group is building the MobilityDB system. It builds on PostGIS, which is a spatial database extension of PostgreSQL. MobilityDB extends the type system of PostgreSQL and PostGIS with abstract data types (ADTs) for representing moving object data. It defines, for instance, the tgeompoint type for representing a time dependant geometry point. MobilityDB types are well integrated into the platform, to achieve maximal reusability, hence a mainstream development. For instance, the tgeompoint type builds on the PostGIS geometry(point) type. Similarly MobilityDB builds on existing operations, indexing, and optimization framework.
MobilityDB supports SQL as query interface. Currently it is quite rich in terms of types and functions. It is incubated as community project in OSGeo, which certifies high technical quality.
The following project ideas contribute to different parts of MobilityDB. They all constitute innovative development, mixing both research and development. They hence will help developing the student skills in:
- Understanding the theory and the implementation of moving object databases.
- Understanding the architecture of extensible databases, in this case PostgreSQL.
- Writing open source software.
Visualization of Moving Objects on the Web
There are several open source platforms for publishing spatial data and interactive mapping applications to the web. Two popular ones are MapServer and GeoServer, which are written, respectively, in C and in Java.
However, these platforms are used for static spatial data and are unable to cope with moving objects. The goal of the project is to extend one of these platforms with spatio-temporal data types in order to be able to display animated maps.
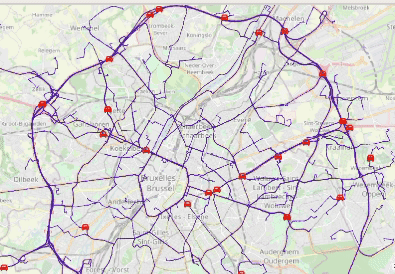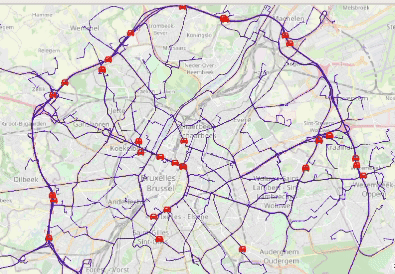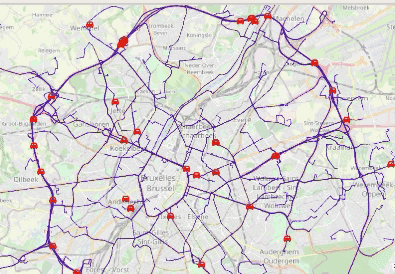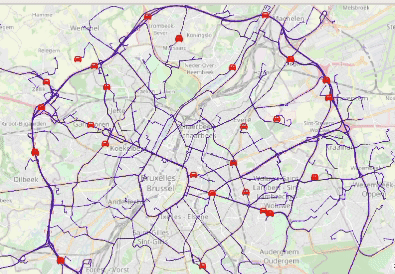
Animated visualization of car trajectories
Status: taken
MobilityDB on Google Cloud Platform
Deploying MobilityDB on the cloud enables the processing of the large amounts of mobility data that are continuously being generated nowadays. MobilityDB has been already deployed on Azure and on AWS. This project continue this effort on the Google Cloud Platform. The objective is to build on the similarities and differences of the three cloud platforms for defining a foundation for mobility data management on the cloud.
Links:
Status: taken
Implementing TSBS on MobilityDB
The Time Series Benchmark Suite (TSBS) is a collection of Go programs that are used to generate datasets and then benchmark read and write performance of various time series databases. This bechmark has been developed by TimescaleDB, which is a time series extension of PostgreSQL.
A significant addition of TimescaleDB to PosgreSQL is the addition of the time_bucket function. This function allows to partition the time line in user-defined interval units that are used for aggregating data.
The project consists in implementing a multidimensional generalization of the time_bucket function that allows the user to partition the spatial and/or temporal domain of a table in units (or tiles) that can be used for aggregating data. Then, the project consists of performing a benchmark comparison of TimescaleDB and MobilityDB.
Map-matching as a Service
GPS location tracks typically contain errors, as the GPS points will normally be some meters away from the true position. If we know that the movement happened on a street network, e.g., a bus or a car, then we can correct this back by putting the points on the street. Luckily there are Algorithms for this, called Map-Matching. There are also a handful of open source systems that do map matching. It remains however difficult to end users to use them, because they involve non-trivial installation and configuration effort. Preparing the base map, which will be used in the matching is also an issue to users.
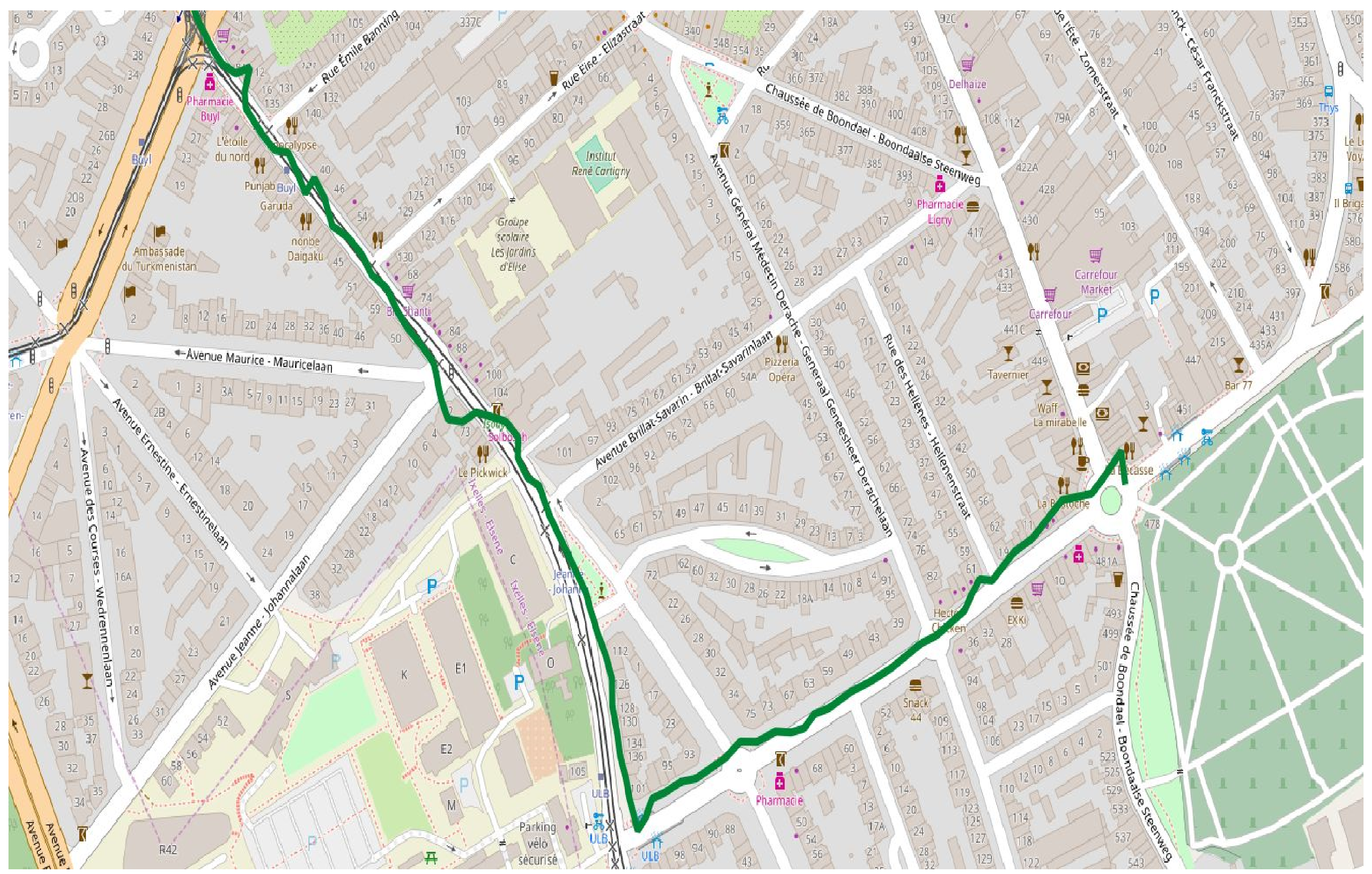
Original trajectory
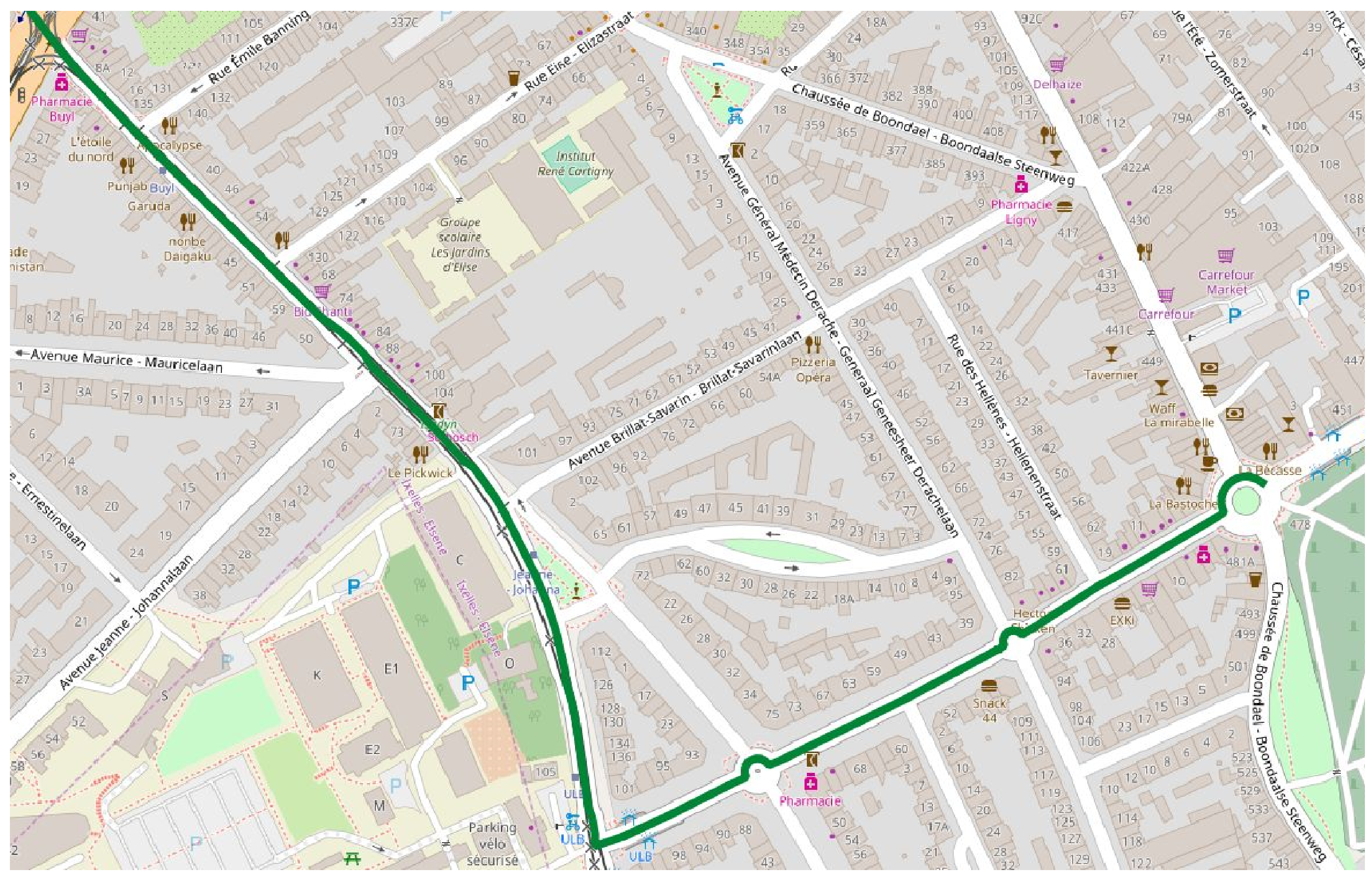
Map-matched trajectory
The goal of this project is to build an architecture for a Map-Matching service. The challenges are that the GPS data arrives in different formats, and that Map-Matching is a time consuming Algorithm. This architecture should thus allow different input formats, and should be able to automatically scale according to the request rate. Another key outcome of this project is to compare the existing Map-Matching implementations, and to discuss their suitability in real-world problems.
Links:
Status: taken
Symbolic trajectories
Symbolic trajectories enable to attach semantic information to geometric trajectories. Essentially, symbolic trajectories are just time-dependent labels representing, for example, the names of roads traversed obtained by map matching, transportation modes, speed profile, cells of a cellular network, behaviors of animals, cinemas within 2 km distance, and so forth. Symbolic trajectories can be combined with geometric trajectories to obtain annotated trajectories.
The goal of this project is to explore how to implement symbolic trajectories in MobilityDB. This implementation will be based on the ttext (temporal text) data type implemented in MobilityDB and will explore how to extend it with regular expressions. This extension can be inspired from the jsonb data type implemented in PostgreSQL.
Links:
- R.H. Guting, F Valdés, M.L. Damiani, Symbolic Trajectories, ACM Transactions on Spatial Algorithms Systems, (1)2, Article 7, 2015
Temporal enumerated types
Symbolic trajectories are currently represented in MobilityDB using the ttext (temporal text) data type. However, when the allowed values for a particular mobility attribute is fixed this representation is not ideal. An example of such a mobility attribute could be transportation mode with allowed values 'walking', 'bus', 'car', or 'plane'. A more efficient way to implement such temporal attributes is to create a new temporal type tenum (temporal enumerated type) based on PostgreSQL enumerated types. However, this temporal type is actually a type constructor, in the same way as PostgreSQL range types. Indeed, a user can define various enumerated types, such as the transportation mode example above and another one such as speed_range with values '0-30', '30-50', '50-70' '70+', and the tenum type can be used to make such enumerated types temporal.
The goal of this project is to explore how to implement temporal enumerated types in MobilityDB. This implementation will be based on the ttext (temporal text) data type implemented in MobilityDB.
Trajectory Data Warehouses
Mobility data warehouses are data warehouses that keep location data for a set of moving objects. You can refer to the article below for more information about the subject. The project consists in building a mobility data warehouse for ship trajectories on MobilityDB.
The input data comes from the Danish Maritine Authority (follow the link “Get historical AIS data”). To download the data you must use an FTP client (such as FileZilla). Follow the instructions in Chapter 1 of the MobilityDB Workshop to load the data into MobilityDB.
You must implement a comprehensive data warehouse application. For this, you will perform in particular the following steps.
- Define a conceptual multidimentional schema for the application.
- Translate the conceptual model into a relational data warehouse.
- Implement the relational data warehouse in MobilityDB.
- Implement analytical queries based on the queries proposed in [1].
Links:
- A. Vaisman and E. Zimányi. Mobility data warehouses. ISPRS International Journal of GeoInformation, 8(4), 2019.
Geospatial Trajectory Data Cleaning
Data cleaning is essential preprocessing for analysing the data and extracting meaningful insights. Real data will typically include outliers, inconsistencies, missing data, repeated transactions possibly with different keys, and other kinds of acquisition errors. In geospatial trajectory data, there are even more sources of error, such as GPS inaccuracies.
The goal of this project is to survey the state of the art in geospatial trajectory data cleaning, both model-based and machine learning. The work also includes prototyping and empirically evaluating a selection of these methods in the MobilityDB system, and on different real datasets. These outcomes should serve as a base for a thesis project to enhance geospatial trajectory data cleaning.
Dynamic Time Warping for Trajectories
The dynamic time warping (DTW) algorithm is able to find the optimal alignment between two time series. It is often used to determine time series similarity, classification, and to find corresponding regions between two time series. Several dynamic time warping implementations are available. However, DTW has a quadratic time and space complexity that limits its use to small time series data sets. Therefore, a fast approximation of DTW that has linear time and space complexity has been proposed.
The goal of this project is to survey and to prototype in MobilityDB the state of art methods in dynamic time warping.
- T. Giorgino, Computing and Visualizing Dynamic Time Warping Alignments in R: The dtw Package, Journal of Statistical Software, (31)7, 2009.
- S. Salvador, P. Chan, FastDTW: Toward Accurate Dynamic Time Warping in Linear Time and Space, Intelligent Data Analysis, 11(5):561-580, 2007.
- D.F. Silva, G.E.A.P.A. Batista, Speeding Up All-Pairwise Dynamic Time Warping Matrix Calculation, Proceedings of the 2016 SIAM International Conference on Data Mining, pp. 837-845, 2016.
- G. Al-Naymat, S. Chawla, J. Taheri (2012). SparseDTW: A Novel Approach to Speed up Dynamic Time Warping. CoRR abs/1201.2969, 2012.
- M. Müller, H. Mattes, F. Kurth, An Efficient Multiscale Approach to Audio Synchronization. Proceedings of the International Conference on Music Information Retrieval (ISMIR), pp. 192-197, 2006.
- Thomas Prätzlich, Jonathan Driedger, and Meinard Müller, Memory-Restricted Multiscale Dynamic Time Warping, Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), pp. 569-573, 2016.
Geospatial Trajectory Similarity Measure
One of the main functions for a wide range of application domains is to measure the similarity between two moving objects' trajectories. This is desirable for similarity-based retrieval, classification, clustering and other querying and mining tasks over moving objects' data. The existing movement similarity measures can be classified into two classes: (1) spatial similarity that focuses on finding trajectories with similar geometric shapes, ignoring the temporal dimension; and (2) spatio-temporal similarity that takes into account both the spatial and the temporal dimensions of movement data.
The goal of this project is to survey and to prototype in MobilityDB the state of art methods in trajectory similarity. Since it is a complex problem, these outcomes should serve as a base for a thesis project to propose effective and efficient trajectory similarity measures.
Spatiotemporal k-Nearest Neighbour (kNN) Queries
An example of continuous kNN is when the GPS device of the vehicle initiates a query to find the three closest gas stations to the vehicle at any time instant during its trip from source to destination. According to the location of the vehicle, the set of three nearest gas stations can change. The result is thus a set of intervals, where very interval is associated with a set of three gas stations. The challenge in this type of query is to find an efficient incremental way of evaluation.
The goal of the project is to survey the state of art in continuous kNN queries, and to prototype selected methods in MobilityDB. Since it is a complex problem, these outcomes should serve as a base for a more elaborate thesis project.
K-D-Tree Indexes for MobilityDB
Indexes are essential in databases for quickly locating data without having to search every row in a table every time a database table is accessed. Thus, an index is an auxiliary data structure that improves the speed of data retrieval operations on a database table at the cost of additional writes and storage space to maintain the index. PostgreSQL provides multiple types of indexes for various data types.
In MobilityDB two types of indexes has been implemented, namely, GiST and SP-GiST. More precisely, in PostgreSQL, these types of indexes are frameworks for developing multiple types of indexes. Concerning SP-GiST indexes, in MobilityDB we have developed 4-dimensional quad-trees where the dimensions are X, Y, and possibly Z for the spatial dimension and T for the time dimension. An alternative approach would be to use K-D Trees. K-D trees can be implemented in PostgreSQL using the SP-GiST framework and an example implementation for simple geometric types exist. The goal of the project is to implement K-D indexes for MobilityDB and perform a benchmark comparison between K-D trees and the existing 4-dimensional quad-trees.
GIN Indexes for MobilityDB
MobilityDB provides GiST and SP-GiST indexes for temporal types. These indexes are based on bounding boxes, that is, the nodes of the index tree store a bounding box that keeps the mininum and maximum values of each of the dimensions where X, Y, Z (if available) are for the spatial dimension and T for the temporal dimension. The reason for this is that a temporal type (for example, a moving point representing the movement of a vehicle) can have thousands of timestamped points and keeping all these points for each vehicle indexed in a table is very inefficient. By keeping the bounding box only it is possible to quickly filter the rows in a table and then a more detailed analysis can be made for those rows selected by the index.
GIN (Generalized Inverted Index) is another type of indexes provided by PostgreSQL. Such indexes are designed for handling cases where the items to be indexed are composite values, and the queries to be handled by the index need to search for element values that appear within the composite items.
VODKA Indexes for MobilityDB
MobilityDB provides GiST and SP-GiST indexes for temporal types. These indexes are based on bounding boxes, that is, the nodes of the index tree store a bounding box that keeps the mininum and maximum values of each of the dimensions where X, Y, Z (if available) are for the spatial dimension and T for the temporal dimension. The reason for this is that a temporal type (for example, a moving point representing the movement of a vehicle) can have thousands of timestamped points and keeping all these points for each vehicle indexed in a table is very inefficient. By keeping the bounding box only it is possible to quickly filter the rows in a table and then a more detailed analysis can be made for those rows selected by the index.
However, the drawback of keeping a single bounding box for the whole trajectory makes that the index is not very selective as shown in the following figure (extracted from a presentation by Oleg Bartunov from PostgresPro)

The goal of the project is to define VODKA indexes for MobilityDB, which enable us to store in the index multiple bounding boxes (one per segment) associated to each row in the table as shown in the following figure

Status: taken
Finding Logic Bugs in Database Systems
Database management systems are complex in their implementations. Implementation errors (Bugs) are therefore inevitable, no matter how mature the implementation is. Logic bugs are one kind of bugs, that cause a query to return incorrect results (e.g., less or more data in the results). Since they don't result in a system crash, logic bugs are difficult to discover.

source: Finding Logic Bugs in Database Management Systems (Manuel Rigger, ETH SQLancer)
SQLLancer is an interesting tool that finds logic bugs by implementing a set of automated logic techniques for generated test queries. One techniques, for instance is the Ternary Logic Partitioning (TLP). TLP partitions a query into three partitioning queries, each of which computes its result, where respectively a predicate p, NOT p, and p IS NULL holds. Clearly the union of the three results must be the whole relation, otherwise a bug is spotted !
The aim of this project is to extend SQLLancer (and the theory behind it) for testing moving object databases. In more detail, the goals are:
- Identify the relevant state of the art
- Test SQLLancer, and repeat all its experiments
- —– Milestone PROJ-H-402
- Extend the logic bug finding methods for spatiotemporal trajectories
- Find logic bug in MobilityDB
- —– Milestone MEMO-H-504
Links for further readings:
Status: taken
Improving Database Query Performance Using Learned Indexes
Secondary indexes are essential for fast query evaluation in databases. An index is a data structure that stores attribute values in a way that enables fast search, and links these values to their tuples in the storage medium. Recent works revealed that the learned index can improve query performance while reducing the index storage overhead.
In [1] a learned 2D index is proposed, SPRIG. It samples the spatial data to construct an adaptive grid and use the sample data as inputs to fit a spatial interpolation function. Given a spatial search key, first, it will use the fitted spatial interpolation function to predict the approximate position of the key. Then, around the estimated position, it conducts a local binary search to find the target key.

source: [1]
While the SPRIG index is built for 2D spatial data, it should be possible to generalize it to nD, e.g., spatiotemporal, because the main structure is a grid. The goal of this thesis is to design and build learned indexes for geospatial trajectory data. In more detail, the goals are:
- Identify the relevant state of the art
- Implement and benchmark the SPRIG learned index [1]
- —– Milestone PROJ-H-402
- Design a spatiotemporal learned index
- Implement in MobilityDB
- —– Milestone MEMO-H-504
Links for further readings:
Responsible Data Science
Explainability in Recommender Systems
Explainability in ML Pipelines using Augmented Data
Machine learning (ML) is in sense a black box, meaning that although it can perform reasonably well for many tasks, it does not provide a meaningful explanation on why a specific prediction was made. This aspect is creating a lack of trust towards ML from legal, financial, and medical domains where the predictions are made about people and explanations are required to back up the trustworthiness of the prediction. Plenty of work has been done towards explainable AI (XAI)). Some methods are feature-based, i.e., identify the features most responsible for a model outcome, while others are data-based, i.e., identify the training data most responsible.
The objective of this work is to apply and compare explainability methods in ML pipelines that incorporate a data augmentation step in the training process. The techniques will be tested on natural language processing (NLP) pipelines.
Requirements:
- strong programming skills in Python,
- familiarity with ML frameworks like TensorFlow, PyTorch,
- familiarity with NLP techniques.
Links:
Fairness in Group Recommender Systems
Location Fairness Auditing
Data Science Workflows
Weak Supervision for Classifying Data Privacy Policies
Dependency of machine learning (ML) on huge labelled training datasets is a blocking point of deployment of ML in many cases. Labelling data manually is time-consuming and costly. Weak supervision tries to automate the label generation by combining various noisy sources into one generative model and then feeds an ML model with the labels generated by the generative model.
The aim of this project is to apply weak supervision to process privacy policies in many levels and identify whether they are GDPR compliant or not. Techniques will be tested uver the OPP-1154 public dataset, which consists of 115 privacy policies manually annotated by the domain expert on a paragraph level (3,792 paragraphs, 10-12 high-level classes, and 22 distinct low-level attributes).
Requirements:
- strong programming skills in Python,
- familiarity with ML frameworks like TensorFlow, PyTorch,
- familiarity with NLP techniques.
Links:
Industry Collaborations
The following projects are offered by our collaborators in the industry.
Euranova
Euranova is a Data Science consultancy market leader, that aims at implementing active technological watch dedicated to the digital transformation of businesses.
Links:
Upstreem
Upstreem is a designer of an electronic offender monitoring system.
Timeseries databases for an Electronic Monitoring System
The Electronic Monitoring system developed by Upstreem consists of the supervision of different nodes (bracelets) deployed throughout a country from 1 or 2 centralized platforms.
The persons under surveillance are monitored by means of a communicating electronic bracelet, which sends back data on the location of the persons under surveillance to centralized platforms developed by Upstreem. These data can then be consulted by the surveillance officers.
The bracelet collects a lot of data such as GPS positions, battery levels, etc. Each value is time-stamped. The monitoring application needs to retrieve the latest values, sets of recent values and values for a given period. Timeseries databases are optimized for this type of data.
Is it relevant to use a timeseries database rather than a relational database?
The work consists of:
- The definition the state of the art and comparison of the different timeseries databases
- The definition of a comparison grid between the existing timeseries databases
- Comparing the use of a timeseries database and a relational database to determine the benefits of using a timeseries database in the context of monitoring data
- The impact assessment of integrating a timeseries database with the existing monitoring system (implementation, data consistency, development tools and deployment)
- The implementation of a proof of concept for the integration of a timeseries database